Business Problem
Building a context-based text model is much like fishing. Nets, woven from lines of rule code, are tossed into oceans of data. There they sit, working quietly as the catches accumulate. Time passes, the nets are retrieved and emptied on the deck. What was the result? Catch of the day, or trash fish to be thrown back?
Successful catches are a good use of time and resources. Unsuccessful catches are not. Tools such as Advanced Filters help tilt the odds towards success. This project would filtering capabilities to the product.

User Research
Four users were interviewed to understand the code writing/results evaluation cycle. Each of these users had significant experience with the product, using the product daily to produce value within internal or customer facing projects. Users demonstrated work methods, and detailed model building tasks.
As stated in previous examples, experienced users completed two coding/review cycles per minute. Each cycle was a guess, like a net trolling a data lake, thrown in and pulled up to evaluate what was dredged up. The results were evaluated, the nets were tuned, and the lake was trolled again. Users attempted to capture the particular terms, phrases, or concepts that could produce business value. These efforts were not very productive as they evolved from a series of organic queries built on guesses.
Although organic queries caught some results, many valuable results were missed. Users continued to refine the queries and results as best they could, but often missed valuable catches due to misspellings or typographical errors within the data. These misses were not something users could predict or plan for, and models missed results because of this.
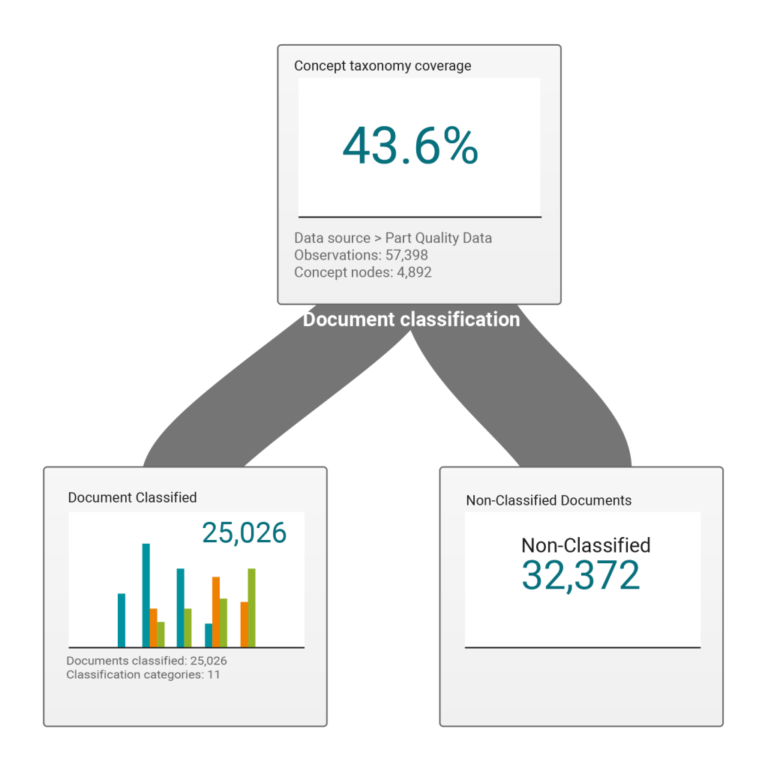
Some modeling tasks involved creating analytical models based on themes constructed from separate but interacting terms, phrases, or concepts. For example, a major brand automotive company seeks to mine data from service center technicians to understand part quality data and make decisions about transmission quality complaints. Recalls, campaigns, or technical service bulletin may result. These are expensive decisions.
Writing model code for single terms isn’t sufficient. The combination of certain related terms used together or in close proximity is what was important. Coding, testing, and validating these scenarios across terms was extremely difficult as there was no way to create a test query, or to save those which may be frequently used.
Finally, users discussed issues associated with inefficient model building based on writing blind code statements and developing queries organically. Creating code syntax while exploring the data is time consuming and cognitively demanding. Simple queries can find valuable data quickly, and users can look for patterns which inform code syntax. The features of both desired and undesired results can be found quickly and codified, resulting in a more efficient modeling process. Using this inverted work method speeds model development and results in more accurately characterized data sets. Advanced Filtering features could resolve many of these issues.
Design Concepts
The feasible solutions set for this project was extremely small. This was due to the number of constraints and intersections created by previously implemented product features and other decisions made outside the development team. Designing an appropriate solution was very challenging.
One constraint involved supporting four task areas with three separate interfaces. Each interface had separate mechanisms to drive the contents of the Documents panel. Metadata and other ancillary features created additional intersections and constraints.
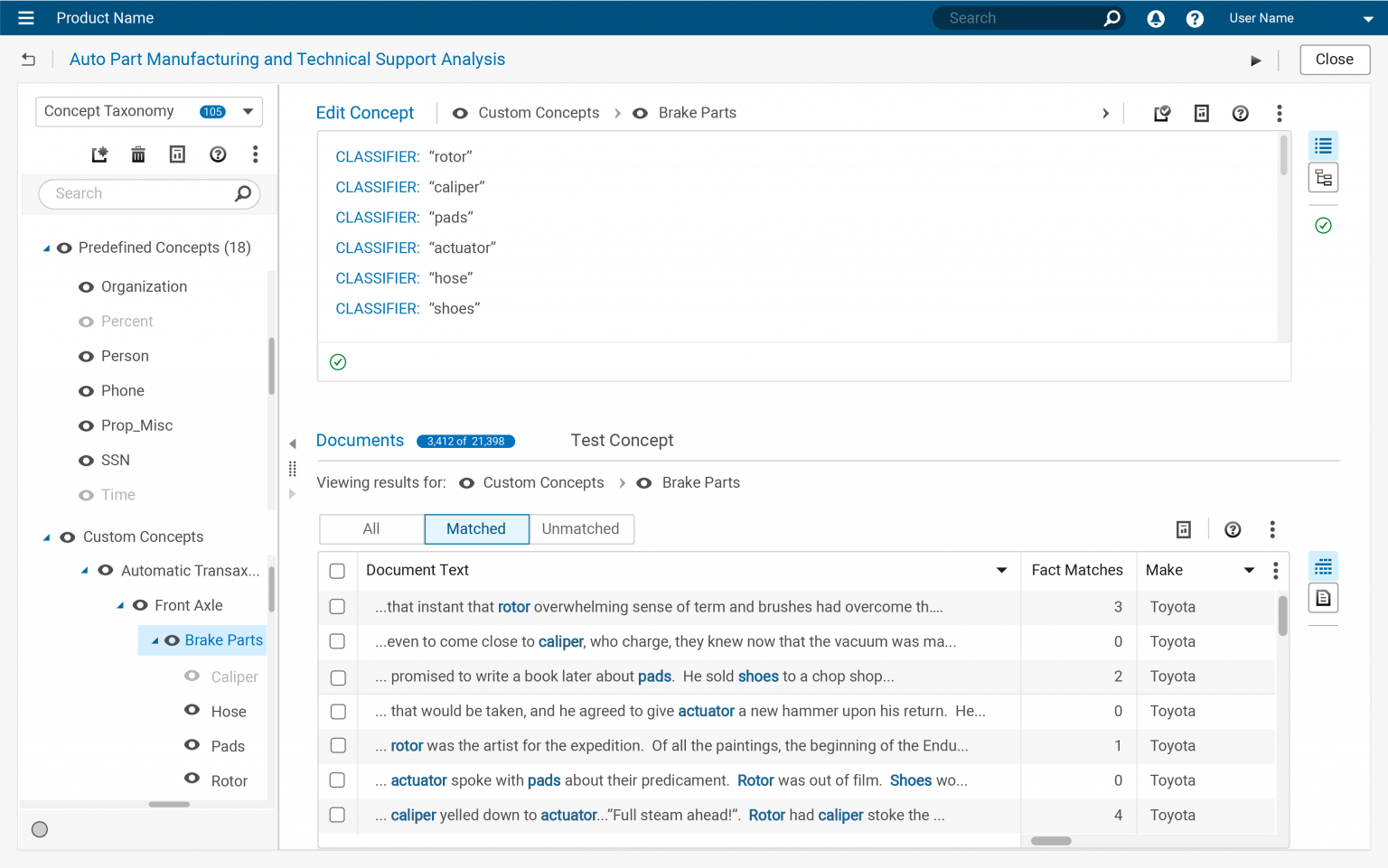
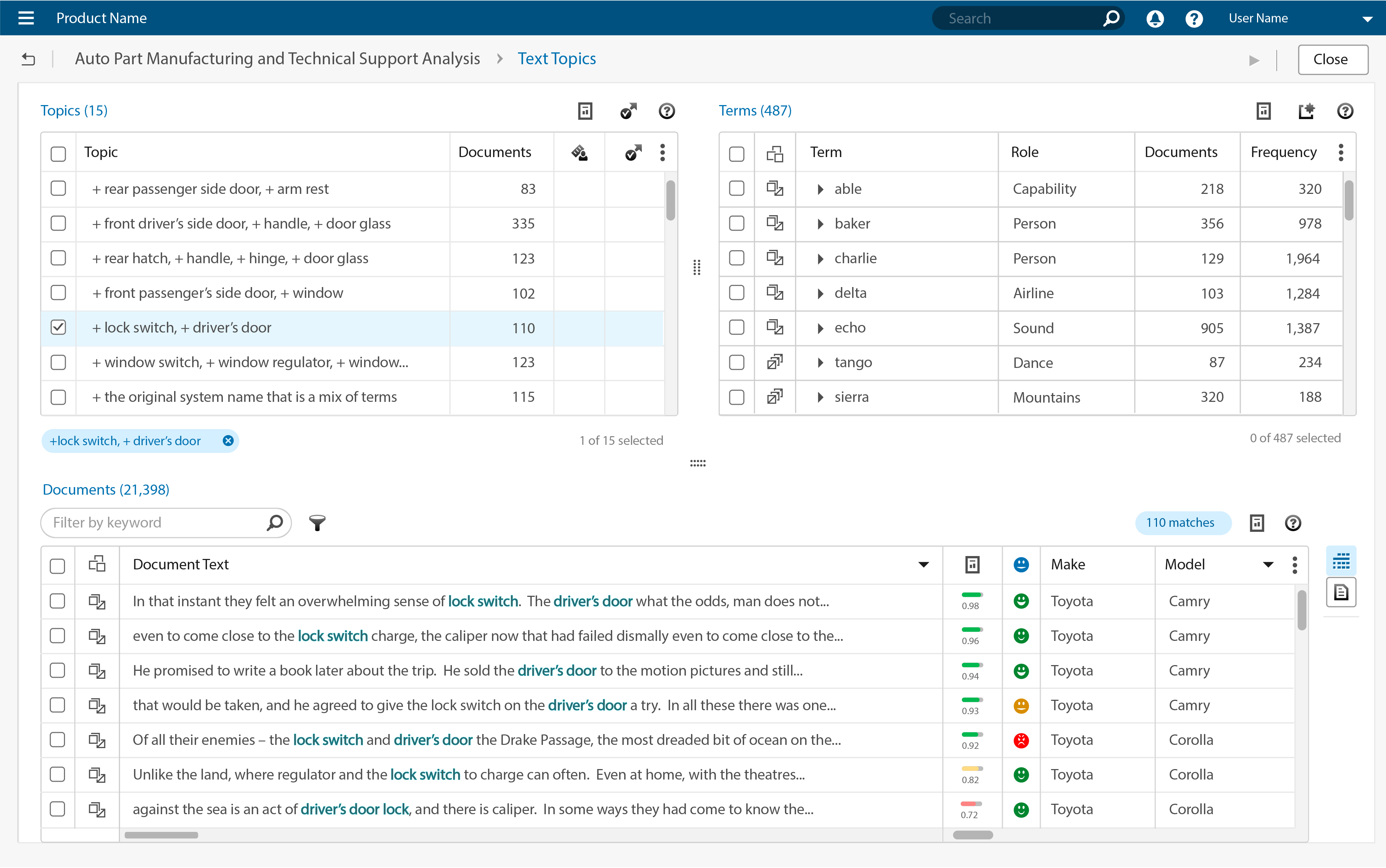
The Documents panel had three display modes which intersected with the filter results. The display modes included “All”, “Matched”, and “Unmatched” documents. While the intersection with the “All” mode was not important, the intersections with the “Matched” and “Unmatched” modes were extremely important – what appeared in these areas drove user coding activities.
Another intersection was created by the display format. Document results could be displayed as a single line per row, multiple lines per row, or as a full document. Any solution would need to work with each of these display modes.
Other factors, such as code fresh/dirty status, or other planned features created additional intersection points the solution would need to be compatible with.
Decisions made by teams outside the product area further limited options. To make a long story short, there were many interactions and considerations; too many to detail here. This was a very challenging project.
Steps Towards a Solution
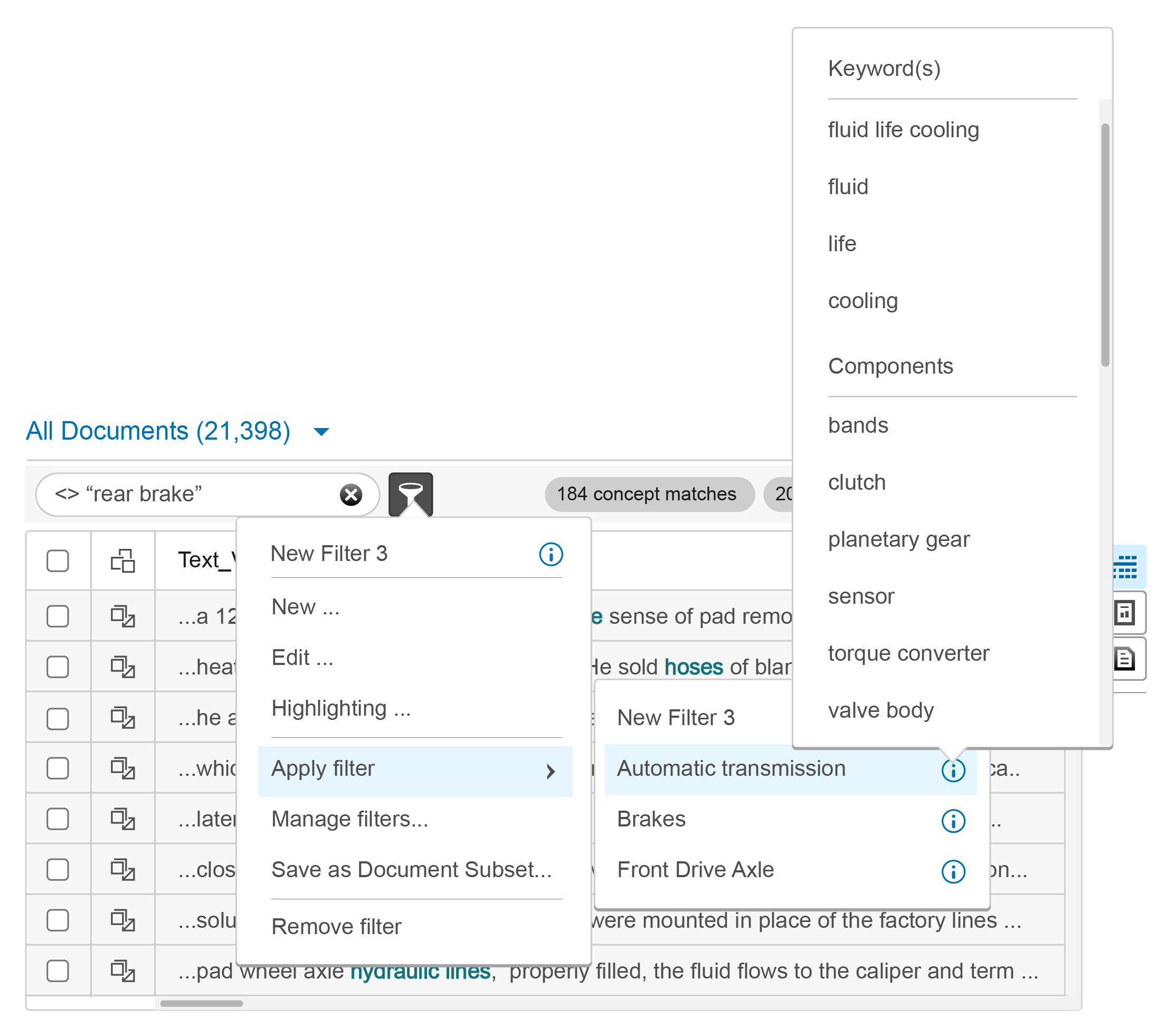
The placement of Search and Filter widgets was fixed to the top left of the table, with no flexibility for alternative placement. Placing the Search and Filter widgets in their assigned locations required moving the display mode selection controls (“All”, “Matched”, “Unmatched”) elsewhere. Moving them elsewhere interfered with other features. Space was extremely limited.
The Document view modes were required, but they had created problems for numerous design projects – time to get rid of these controls once and for all. A new display strategy was developed.
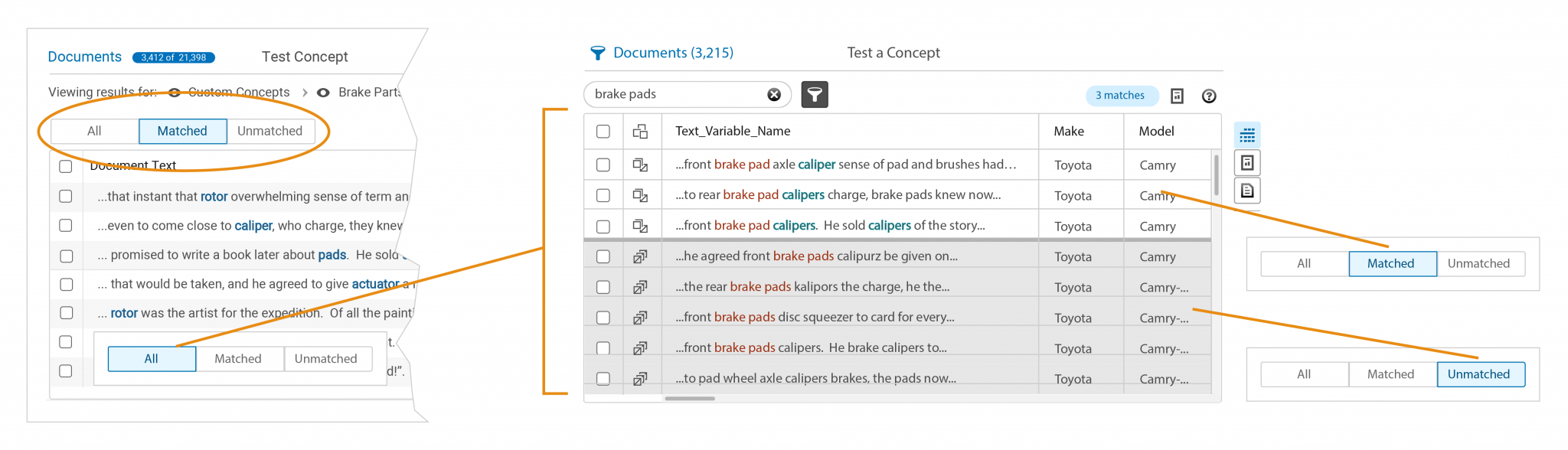
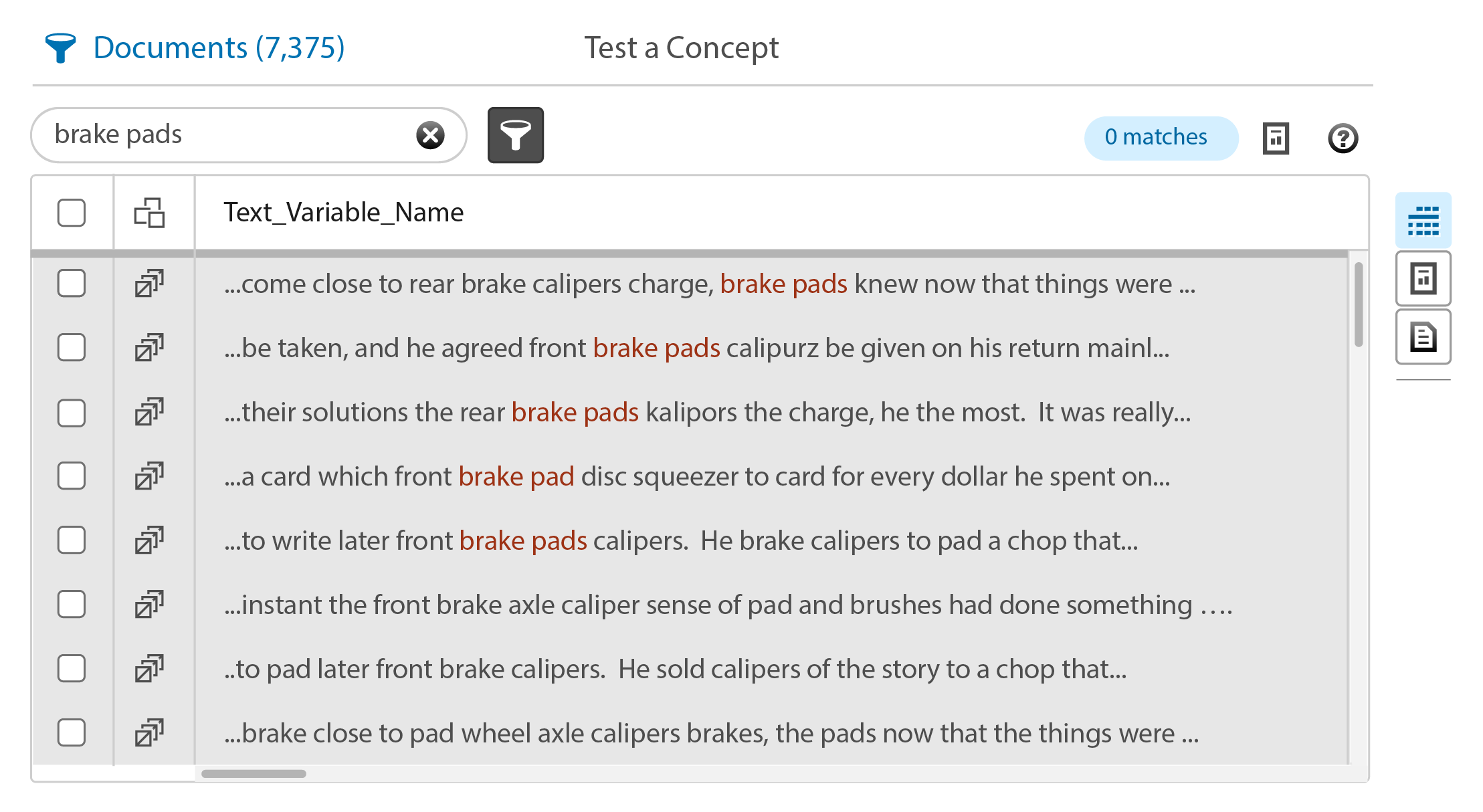

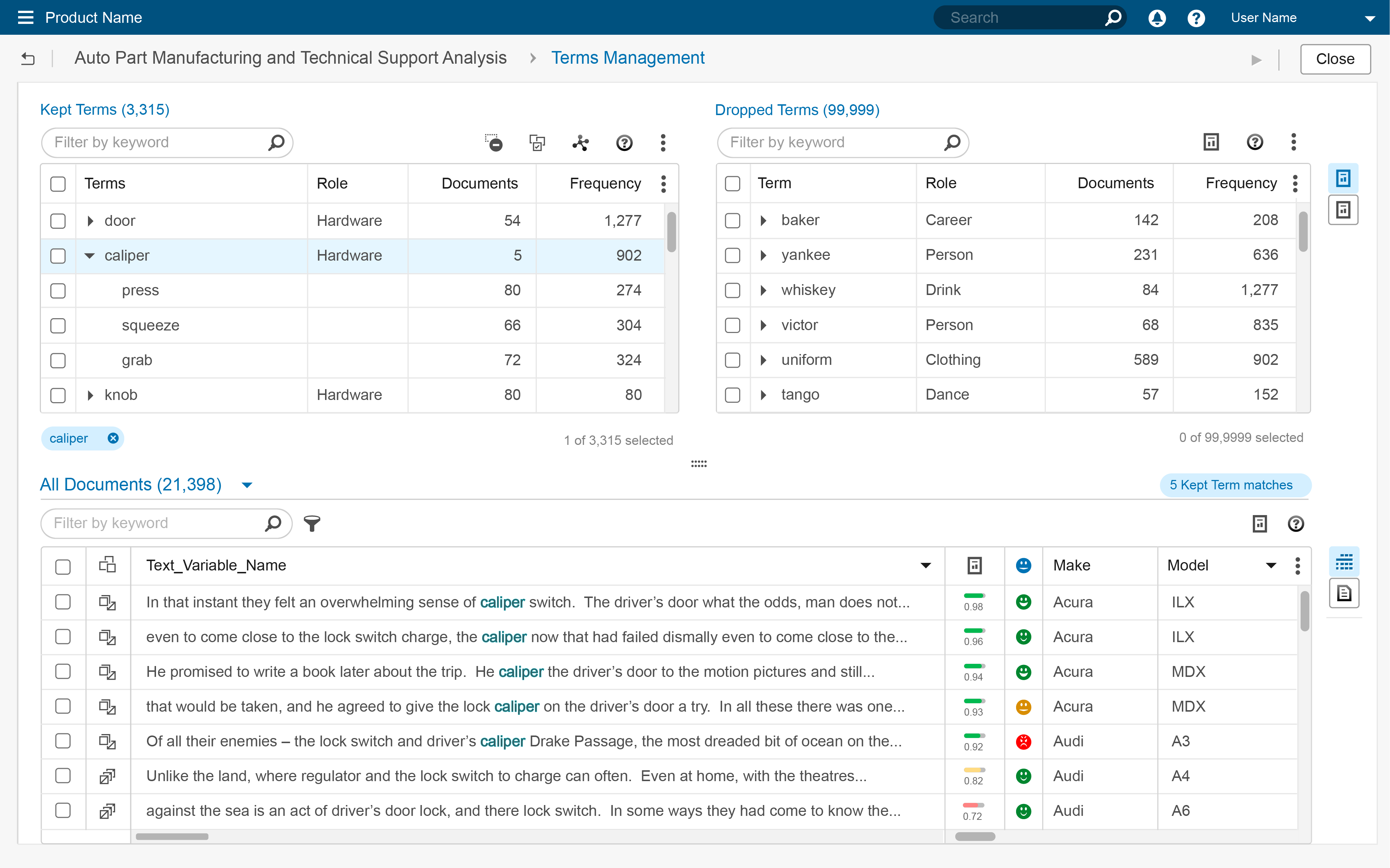
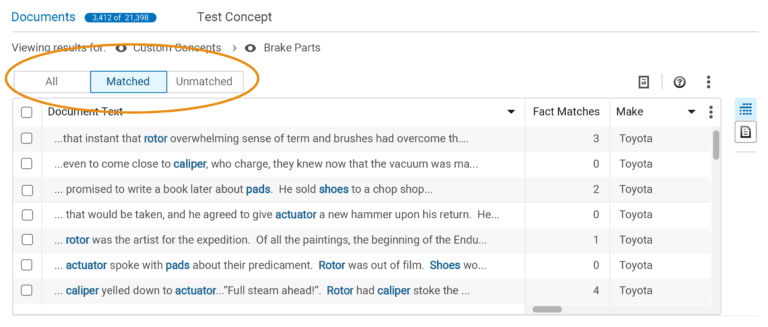
The new display strategy created a new viewing metaphor which removed the controls altogether. “All” documents would be displayed at all times using gray table rows. Documents which matched the driving selection (code matches, selections in Terms, Topics, or other tables which match documents) would display “in matching set” results using white rows sorted to the top of the display. “Out of matching set” results would be sorted below these.
Determining a color for the filter and search match results seemed easy, but it wasn’t. The legacy version of the product used multiple colors and text treatments to highlight several different term statuses. These results would need to fit within those constraints, and be perceivable and legible against the different row treatments.
The Visual Design department selected a red color, as it was one of the few choices remaining from the color palette. Not an ideal color, but it was legible against both gray and white backgrounds.
Sort order and mixing of matched and unmatched items was the next hurdle. Without the “Matched” and “Unmatched” controls, items matching either the filter or the driving mechanism could be mixed within very long data sets. Looking through long tables is not ideal usability. A forced sort order fixed this.
Items matching the search and filter criteria are automatically sorted to the top of the record stack. Users review these matches, then write code statements to capture these items.
Users can then scroll the Documents view to see what sorts of records have not been captured, and write queries that categorize them appropriately. This was the primary task users tried to accomplish.
Adding this feature could resolve many of the coding-related issues raised by users over time. Although application performance issues wouldn’t be resolved, coding tasks could be less cognitively complex and completed more efficiently; less guesses and adjustments, and fewer demands on system resources affecting performance.
Supporting Structures
Search and filter widgets are not stand alone components, they integrate with other structures such as dropdown menus and faceted filters. Other features that users requested could be supported through clever combinations of these structures.
Building filter queries based on keywords or faceted filter selection provided users with the ability to create document subsets to code against. Document subsets provided an opportunity to test the code from multiple taxonomic items against a similar document grouping, ensuring that combined taxonomy entries worked as desired. This was a greatly desired feature that users requested repeatedly.
Outcome
The design solutions were reviewed with end users and the development team. During the session the room remained quiet. Heads just simply nodded up and down in unison; even that of the risk averse Development Manager who often put the kibosh on product improvements.
Adding this feature could resolve many of the coding-related issues users complained about. Although application performance issues wouldn’t be resolved, coding tasks could be less cognitively complex and completed more efficiently. This would result in fewer guesses and adjustments, and fewer demands on the system.

Related Examples
Diagnostic Measures
Users pleaded for task support metrics. Product Management answered with alms of useless chart-junk. This story describes my efforts to manage an unfortunate design situation
Integrating Redesign Features
Ignoring design efforts for too long results in an accumulation of UX debt. Inevitably, the bill comes due. This story discusses using previously ignored design efforts to settle accounts.